

Applying Self-Supervised Contrastive Learning On Various Applications
Computer vision applications can be considered as endless journey. Human brain can analyze a lot of information from the environment around us, while it needs huge effort to make it for machines. As it is not very efficient to create 1 giant model for everything, developing techniques to create domain specific model becomes an urgent topic.
Why Contrastive Learning?
Main problems of creating new application specific model are availability of precise data. We can find data which is unlabelled but it does not let us to fully focus on model development. That is why, it is fundamental rule of every data science project that data is most important aspect. However, there are some ways which can diminish annotation time of the images.
Unsupervised Contrastive learning is an approach to increase the efficiency in case of inaccurate or absence of data. We are talking about SimCLR paper or Simple Framework for Contrastive learning of Visual Representations [https://arxiv.org/pdf/2002.05709.pdf] by Google Research. The 3-stage framework enables us to improve any application with less number of manual annotation.
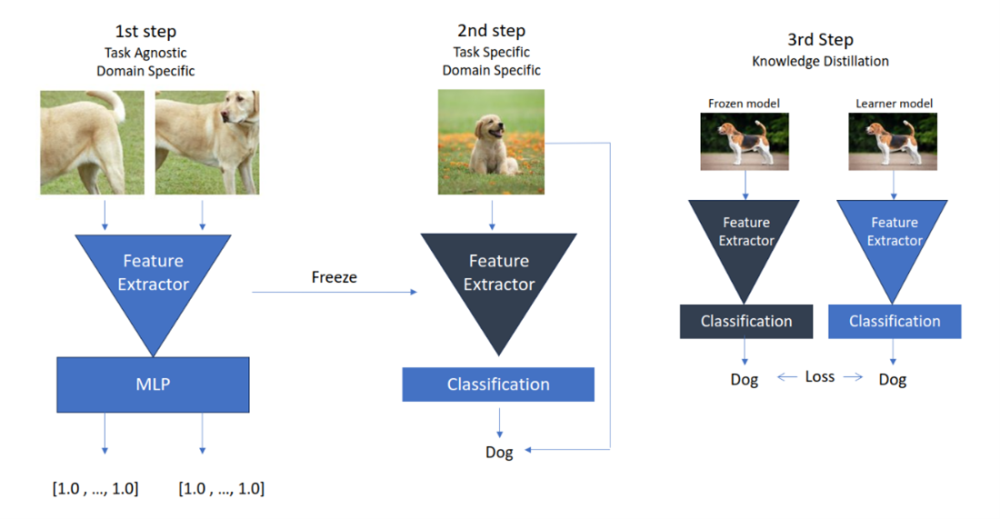
Figure 1. Overall view of SimCLR Framework
How it Works?
Main aim of this work is to use large amount of unlabelled images from the domain that we want to build application to make robust feature extractor. This happens in first step but how?
1. Images are taken in batch size of mininum of 128.
2. Each image is augmented and 4, 8, 16 different versions of the same data are created (Cropping, Resizing, Color Jitter and etc.). Labels are defined if the augmentation is coming from the same source or not.
3. Images are fed through feature extractor and MLP layers. Results of MLP should be closer for the same sources while far away for different sources.
This 1st step is domain specific due to the fact that feature extractor is forced to generate efficient features to distinguish among the different sources. In practice this gave greater efficiency than traditional supervised learning.
2nd Step of SimCLR framework:
1. Feature extractor is taken from the 1st step and gradient calculation is frozen.
2. MLP layer has been removed and replaced by task specific classification layer.
3. Supervised learning technique is used with less number of labels to give task specific capability.
In paper of SimCLR it is proved that this way of training outperformed many benchmark trainings using ImageNet on ResNet and Wide ResNet models. To increase the performance more, 3rd step is promoted to either keep the same model architecture to increase the performance or decrease the model complexity to keep the same performance or diminish accuracy loss.
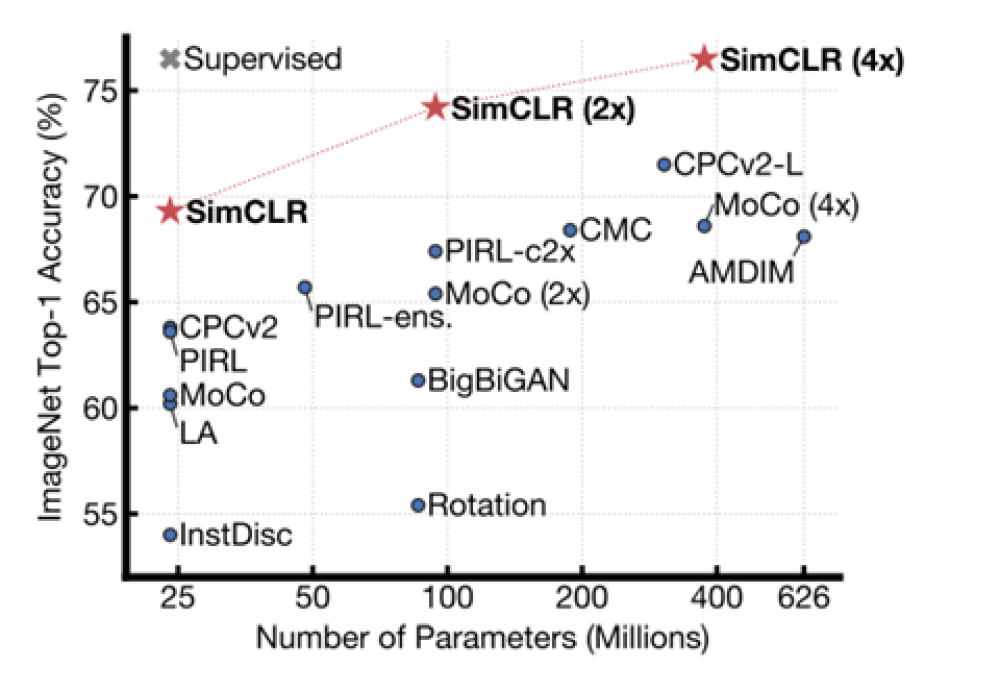
Figure 2. Accuracy comparison with 2020 benchmarks. Source: SimCLR paper
Note: Making knowledge distillation on for the same architectures can seem meaningless while it has crucial benefit. It adds natural regularization for the errors that teacher model makes during prediction. Eventually it increases the performance on the same architecture.
3rd step is done with these procedures:
1. We take trained model from the second stage and freeze the gradient calculation.
2. Create either the same or smaller architecture model with random weights.
3. Give the same input to both models. Output from frozen model should be considered as ground truth.
4. Find the loss between ground truth and prediction of new model and update new model.
Advantages:
1. Robust Feature Extraction capability
2. Building the application with less data
3. Outperforming Traditional supervised learning methods.
Disadvantages:
1. High computation requirements
2. It repels features of the same class too. As the Self-Supervised Contrastive learning approach tries to make the features of different images far away, images from the same class will be also away. In some terms, it can decrease the efficiency of the model.
In order to diminish the 2nd disadvantage, the same authors developed Supervised version of Contrastive learning which were based on prototypes [ https://arxiv.org/pdf/2004.11362.pdf ]. In that paper, they use small amount of labels, to make the features of the same images and the same classes very close to each other while other classes are repelled far away.

Figure 3. Supervised Contrastive learning difference from Self-supervised. Source: SimCLR paper
While the steps can seem quite difficult, it can increase the efficiency of the model development in case of less number of the annotations.
References:
SimCLR Paper:
https://arxiv.org/pdf/2002.05709.pdf
Supervised Contrastive Learning:
https://arxiv.org/pdf/2004.11362.pdf
Github of SimCLR: